Pandas¶
Introduction to Pandas¶
First things first, Pandas is a package, which is the most important tool for data manipulation and analysis (Python Developers Survey 2020 Results)
The name of Pandas is derived from 'Panel Data'.
Glossary
panel data: In statistics and econometrics, panel data or longitudinal data, are multi-dimensional data involving measurements over time. 1
What is numpy and pandas¶
In terms of release time, Numpy preceded Pandas. Numpy is an open-source Python library used for scientific computing and provides high-performance operations on arrays and matrices (ndarray object). ndarrays are stored and processed more efficiently than Python's default list objects through vectorized operations.
Pandas library is built on Numpy Package, as a higher-level wrapper for the convenience of data science users. Instead Pandas abstracts away those mathematical terms (e.g., vectors, matrices) and turns them into some familiar concepts such as columns, spreadsheet. This way everybody is HAPPY!
One step further: why numpy(ndarray) is faster?¶
- Requires all the elements in a ndarray object to have the same data type, either integer or floating point numbers, but not a mix of the two. This saves tremendous time inspecting if an operation is workable with specific elements.
a_list = [2,3,4,'t']
#now we want to apply x+10 to all elements of this list
result = [x+10 for x in a_list]
result
A TypeError was triggered. During each iteration, Python interpretor checks whether the intended operation is workable with the element. Say you have a list of 1 million elements, Python has to check the compatibility issue for 1 million times, which is a huge waste of time and computing resources. Numpy came up with a new data type to this problem that is it requires every single element in the list has to be of the same data type. This saves tons of computing time and resources. In addition, it opens the door for vectorized operations which allows more data to be processed at once.
- Once Numpy knows an array's elements are homogeneous in data type, the next step Numpy does is to delegate the array to numpy's optimized C code, which is blazingly fast.

Learning Pandas¶
Numpy is only concerned with high-performance numeric computation (e.g., Matrix transpose, matrix multiplication, and so on), however, pandas is designed more for data scientists who care about data manipulation, missing data, queries, splitting and so on. For instance, some of you might be familiar with SQL statements which can be used in Pandas directly.
Also, as mentioned earlier, Pandas acts as a higher-level wrapper of Numpy cores, which intends to make the learning a lot easier.
Import pandas and numpy modules¶
import pandas as pd
import numpy as np #Some of the demos below will use functions from numpy.
pd.__version__
Pandas's Data Structures¶
Pandas has two main data structures.
- Series: is a one-dimensional labeled array that is able to hold any data types (integers, strings, floating point numbers). Think of a series as a column in your spreadsheet. Did you ever pay attention to the leftmost side of a spreasheet indicating the line number/index? Series object has the same design, which in Pandas is called index. The index can be a list of integers, letters or literally anything. The values of index are called labels.
- Dataframe: is a two-dimensional data structure, quite similar to a tabular spreadsheet with rows and columns. In addition to the row labels shown on the leftmost that is used to indentify rows, a dataframe object also has column labels that are used to index columns.
Essential Functions¶
Reading/Writing Data¶
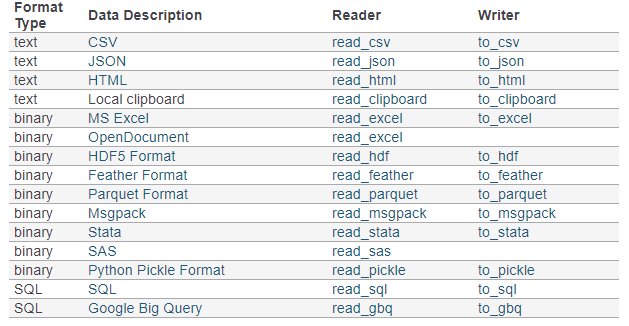
Pandas can handle virtually any data file format. Below is a table containing supported data formats and their reader & writer functions.
Import Parameters¶

It has more than 50 parameters!? Here are some important parameters you need to pay attention to.
- filepath_or_buffer: Any valid string path is acceptable. The string could be a URL. for example: Windows: "D:/data/xx.csv" OS: "usr/you/document/xxx.csv"
Tip: for Mac users, if you do not know the path of a file, you could simply drag the target file into a terminal. The prompt tells you the path of that file. - sep: Separator/delimiter to use to parse the file. Defaults to ','. If your data is TSV (tab-separated values) file, pass '\t' to this parameter.
- header: the row number to use as column names. Defaults to 'infer'. If your data has no columns present in the file, set this parameter to None and then pass a list of names to the name parameter.
- names: used when your data has no columns.
- usecols: return a subset of the columns. Instead of reading the whole dataset, this parameter tells pandas to read the columns of your interest. It is particularly useful when you are dealing with a massive dataset.
- encoding: defaults to 'utf-8'. check here to get a list of all supported encodings.
Example¶
Read a web csv file via a URL address https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv
import pandas as pd
data = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
data.head()
Exploring Data¶
The first thing to do after your data is loaded into Notebook, is to get to know the basic information (e.g., the dimension, size, shape, data types of all the columns) of your data and what your data looks like roughly. All the basic information can be retrieved from DataFrame object's attributes.
Hint: What are attributes of an object? Attributes are the info/properties pre-calculated when you instantiate an object.
Getting the basic info of the data through attributes¶
- shape: return a tuple representing the dimensionality of the Dataframe
- ndim: return an integer representing the number of dimensions
- dtypes: return a Series including the data type of each column of the DataFrame.
- index: Return the index labels of the Dataframe
- columns: return a list of column names
data.shape # 4 rows * 4 columns
data.ndim # the dimenion of your data. If you are working with HDF5 file, you might have more than 2 dimensions.
data.dtypes
#Object is a data type defined by Pandas.
data.index
data.columns
Viewing the data¶
- head(n): return the first n rows. It is a quick solution to get a good sense of data and also to test if your data is loaded as you expect. The parameter n defaults to 5.
- tail(n): return the last n rows. The parameter n defaults to 5.
- describe(percentile = None, include=None, exclude=None): Generate descriptive statistics of the included columns that summarize the central tendency, dispersion, shape, ignoring NaN values. By default, this summarization only applies to numeric columns.
- mean(), sum(),min(), max(), idxmin(), idxmax(): get the mean, sum, minimum, maximum, the index of the minimum value, the index of maximum value of all columns
data.head(2)
data.tail(1)
data.describe()
data.mean()
data.sum(numeric_only=True)
data.max()
data.idxmax()
Indexing: Selecting, Slicing and Modifying Data¶
Pandas uses two indexing systems at the same time. One is the position-based indexing (starting from 0)and the other is the label-based indexing. When dealing with Series or DataFrame objects, you can use either positions (like what you do with Python on indexing a list) or labels for selecting, slicing and modifying values.
Position-based Indexing System¶
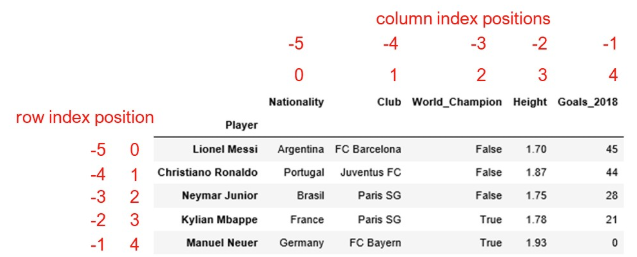
Label-based indexing System¶
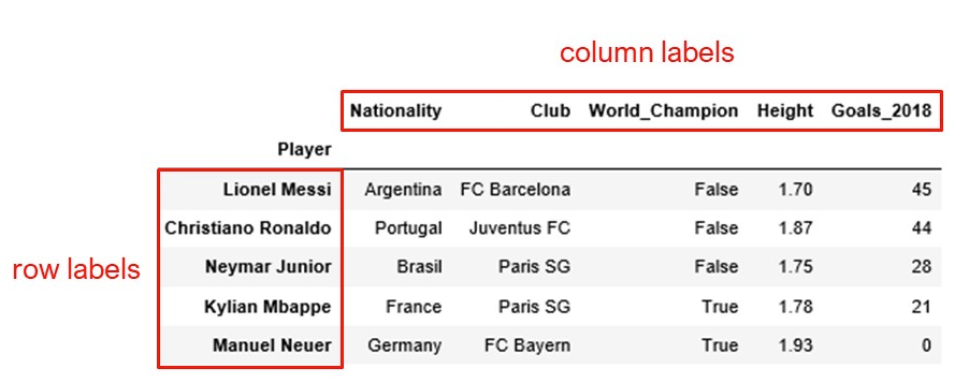
Two methods for indexing¶
- .iloc[]: position-based method for indexing. Allowed inputs are:
- An integer, e.g. 5.
- A list or array of integers, e.g. [4, 3, 0].
- A slice object with ints, e.g. 1:7. Note the end point of the slice is not included.
- A boolean array.
- A callable function with one argument (the calling Series or DataFrame) and that returns valid output for indexing (one of the above). This is useful in method chains, when you don’t have a reference to the calling object, but would like to base your selection on some value.
- .loc[]: label-based method for indexing. Allowed inputs are:
- A single label, e.g. 5 or 'a', (note that 5 is interpreted as a label of the index).
- A list or array of labels, e.g. ['a', 'b', 'c'].
- A slice object with labels, e.g. 'a':'f'. Warning: Contrary to a python slice, For the slice in Pandas, both the start and the end slice points are included.
- A boolean array of the same length as the axis being sliced, e.g. [True, False, True].
- A callable function with one argument (the calling Series or DataFrame) and that returns valid output for indexing (one of the above)
df = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
df.index = df.ID
df
A. passing in a single value
df.iloc[0] # returns the row-0 on the position indexing.
df.loc['U001'] # return the row-U001 on the label indexing
df.iloc[0, 0] #refers to the cell at position (0,0)
df.loc['U001', 'Name']
B. passing in a list of values
df.iloc[[0, 3]] # we want to select the row-0 and row-3 using the position indexing system
df.loc[['U001', 'U004']]
df.loc[['U001', 'U004'], ["Name", "Grade"]]
C. using a slice
df.iloc[:, 0] # return the first column,
df.iloc[0, :] #return the first row
What is a boolean array? (Aka Boolean Mask array)¶
A boolean array is an array filled with True or False values. It is primarily used as a mask indicating whether the corresponding entries is selected or not.
df
x = df.Score > 85
x
df.loc[x]
df.loc[df.Score >85]
df.loc[(df.Score > 80) & (df.Name == 'Kevin')]
Syntax: In pandas, when you combine multiple conditions, you need to use & (bitwise and),| (bitwise or) or ~ (bitwise not).
Question: Why not use and to connect two criteria?
Pre-processing Data¶
Before you start to analyze your data, you might realize that you have to spend a large amount of time cleaning up data. The possible cleansing operations can be:
1. dropping irrelevant columns/rows,
2. adding new columns/rows,
3. fixing data missings, dropping columns/rows in which too many missing entries are present
4. transforming certain columns E.g., add 100 to column x. Column-related Operations:¶
- .drop(columns=, inplace=False): Drop columns by names, pass a list of names to the parameter columns. If inplace is True, the changes is operated on the original data, otherwise, a copy will be returned.
- .dropna(axis='columns', how='any', thresh=None, subset=None, inplace=False) Drop columns by missings. Threshold: the minimum number of non-Nan values. subset: labels along other axis to consider.
- .insert(loc, column, value): Add a new column. loc: the insertion index. Must be between 0 and len(columns)
- .rename(columns={oldname: newname, }, inplace=False) Rename columns:
- data.column-name.apply(func) : apply a transformation function to a certain column.
#Example
df = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
df
#drop the Grade column
df.drop(columns='Grade')
df # why Grade is still in there?
df.drop(columns="Grade", inplace=True) # this time there is no return actually.
df
df = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
#before we use dropna method, let's add some nan values to col_1 by using loc method
df.loc[0, 'Score'] = pd.NA #pd.NA is a data type to represent missing values.
df
df.dropna(axis='columns', how='any')
df #Rule 1: Most operations generate a copy
df.dropna(axis='columns', how='any', inplace=True) #Rule 2: if inplace parameter is present in a function, it allows you to make a inplace change.
df
#insert a new column
df.insert(value=np.random.random(4), column='col_new',loc=0)
df
#rename col_new to col_new2
df.rename(columns={'col_new':'random'},inplace=True)
df
df.sum(axis = 0)
## Apply a function to each column to do transfromations.
#Tip: you can use a attribute-style to reference a column. E.g., data.A
#e.g., add [1,2,3,4] to col_new2
df['random'].apply(lambda x: x+10)
df
# wait!!!! what is that? How come I get a Series object? I was expecting to get a updated dataframe.
# Remember Rule 1? Every operation generates a copy.
df['result']= df['random'].apply(lambda x: x+10) #rewrite the column col_new2
df
help(df.apply)
##waht if I want to update the random column with the calcualted results
df['random'] = df['random'].apply(lambda x: x+10)
df
Row-related Operations:¶
- .drop(index=, inplace=False): Drop rows by labels, pass a list of names to the parameter index. If inplace is True, the changes is operated on the original data, otherwise, a modified copy is returned.
- .dropna(axis='index', how='any', thresh=None, subset=None, inplace=False) Drop rows by missings. Threshold: the number of non-Nan values. subset: labels along other axis to consider.
- .append(other, ignore_index=False, verify_integrity = False): Add another DataFrame to the end of the current DF. if ignore_index=True, the index of the output is reset. If verify_integration is set to True, Pandas raises ValueError on creating index with duplicates.
- .rename(index={oldname: newname, }, inplace=False) Rename row labels:
- .apply(func, axis=1, ) : apply a transformation function to each row. for instance, get the sum of each row.
data = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
data
#drop the first two rows
data.drop(index=[0,1])
data
#add some missing values to the row_2
data.loc[0,'Grade']=pd.NA
data
#drop rows in which the the number of Non-nan is less than the threshold
data.dropna(axis=0, thresh=4) # if a row has less than 4 non-empty values, it gets deleted.
data.rename(index={1:'row_renamed'})
#try append function
df1 = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
df2 = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
df1.append(df2, ignore_index=False) # ignore_index=False tells Pandas to keep the data's original index labels.
df1.append(df2, ignore_index=True)
df1.append(df2, verify_integrity=True) # verify_integrity checks if those data have the duplicates on index. If so, throw out an error
#apply a transformation to each values of each row
df = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
df_num = df.loc[:, ["Score"]].copy()
df_num["Score2"] = [10, 20, 30, 40] # you can also use df_num.insert() method to add a new column
df_num
df_num.apply(lambda x: sum(x), axis=1) # if you feel axis is confusing, always check with help()
Element-related Operations:¶
- .applymap(func): apply a function to each element of the dataframe
#get the length of each element
data = pd.DataFrame(np.random.randint(0,100, (4,3)),
columns=['col_'+str(x) for x in range(3)],
index=['row_'+str(x) for x in range(4)])
data
data.applymap(lambda x: x*2)
data
Missing value¶
- .isull(): element-wise operation, returns a boolean Series. Detect if a value is np.nan. Tip: np.nan is a data type notation to representing nullnuess in Numpy.
- .notnull(): element-wise operation. The opposite of isnull()
- .fillna(value=None, method=None, axis=None,inplace=False) Fill Nan values using specified value(s) or method
Use this link to get another dataset which has missing values https://raw.githubusercontent.com/s4-web/pythontraining/main/datanull.csv
Count how many missings are present in each column¶
data = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/datanull.csv")
data
data.isnull()
data.notnull()
#Count how many missings are present in each column
data.isnull().sum()
#Count the number of missing in each row
data.notnull().sum()
fill missings with 0s¶
data = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/datanull.csv")
data
data.fillna(value=0)
Question: I want to replace missings in different columns differently. Replace all the missing Grade as 'B'; replace all the missing scores as 50.
data.fillna({"Grade": 'B', "Score": 50})
Fill missing with backward-fill method¶
data
data.fillna(axis=0, method='bfill') # bfill method uses the next valid value to fill the holes
Merging/Joining Data¶
- .merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, ): merge two Dataframe objects on a specified column/index.
.join(other, on=None,lsuffix='', rsuffix=''): Similar to the merge function, but join method can take as many dataframes as possible. The limit is it only look at the aligned index to do concatenation.
Merge Vs Join Vs. Append:
- Merge gives you more customization power than join. You could tell this from the number of parameters. Merge method has more parameters than join function.
- Join requires the common colummns having the same name(s). However, Merge does not have this limit.
- The biggest advantage of using join is that you could join as many dataframes as possible.
- Append only patch the new data to the bottom of the old data.
df1 = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
df2 = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/datanull.csv")
df1
df2
"Join" two dataframes using index¶
df1.join(df2, lsuffix="_2018",rsuffix="_2019")
"Merge" two dataframes using index¶
#merge two dfs on the index, same as the join
df1.merge(df2, left_index=True, right_index=True, suffixes=('_2018', "_2019"))
Merge two dataframes on a common column¶
#merge two dfs on a specified common column,
df1.merge(df2, left_on="ID", right_on="ID", suffixes=('_2018', "_2019"))
Iteration of DataFrame¶
- Iterate over rows:
- iterrows(): return a pair(index, Series)
- itertuples(): return a named tuple object: Pandas(Index=0, col_1=2, ...) (Recommended as this method preserves the data types of values. Also this method runs faster than iterrows())
- Iterate over columns:
- iteritems(): return a pair (column name, Series) paris
data = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
data
Iteration over rows¶
##Example: iterate over rows
for row in data.itertuples():
print(row.Index, row.Score) # Note that Index is capitalcase.
#Example iterate over rows using iterrows
for index, row in data.iterrows():
print(row.Name)
Iteration over columns¶
#example iterate over columns
for index, col in data.iteritems():
print(col) #col is a series object
GroupBy Operations¶
.groupby(by=None). The parameter by is used to dtermine how to make groups.
A groupby operation is a combination of splitting the object into groups, applying a function to each group, and combining the results.
- The splitting step breaks up the dataframe into groups depending on the values of the specified key.
- The applying step does some computing operations (e.g., transformation, aggregation(sum, std),) within each group.
- The combining step merges the results of all the groups into an output dataframe.
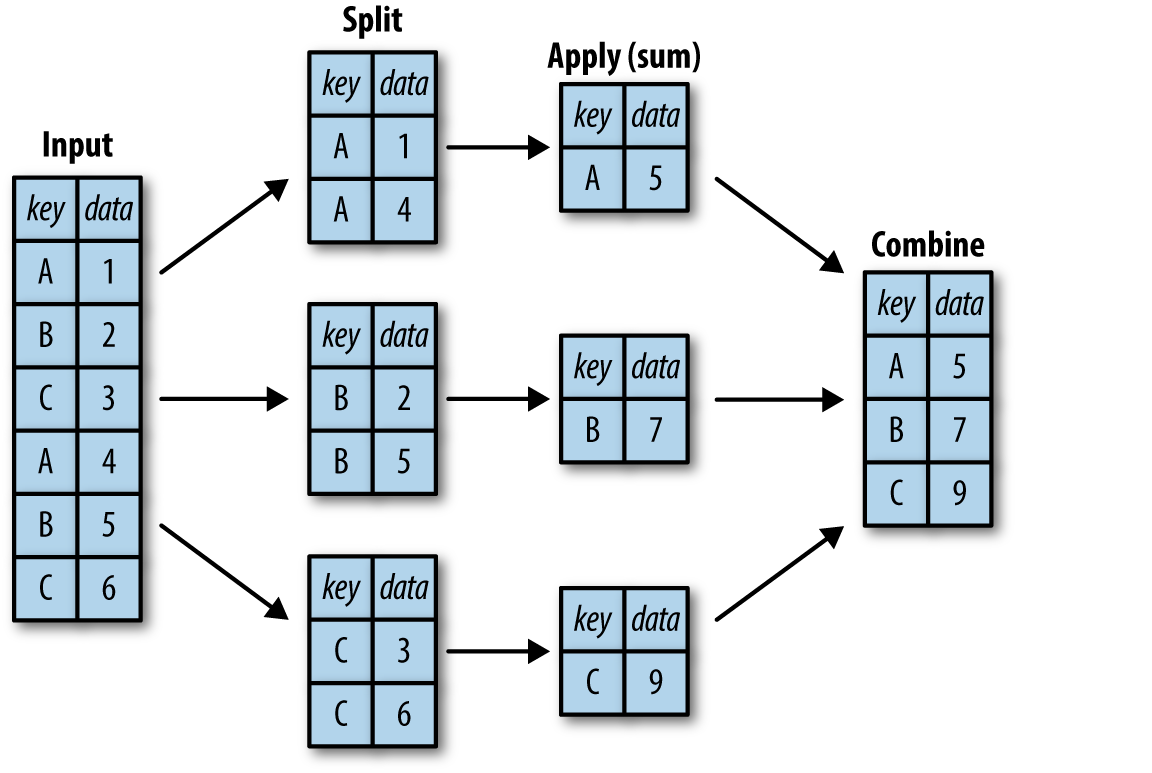
#Example
data = pd.DataFrame({'name':['p1','p2','p3','p4','p5'],
'state':['TX',"RI","TX","CA","MA"],
'income(K)':np.random.randint(20,70,5),
'height': [4, 5, 6.2, 5.2, 5.1]})
data
#get the mean income and mean height of each state
data.groupby('state').mean() # Question: where is name? mean operation is not compatible with a string column.
data.groupby('state').sum()
#what if we want to apply differnt methods to differnt columns
data.groupby('state').aggregate({'income(K)':max, 'height':min })
Visualization¶
DataFrame.plot(x=None, y=None, kind='line'). The 3 most important parameters:
- x : label or position, default None
- y : label, position or list of label, positions, default None
kind : str
- ‘line’ : line plot (default)
- ‘bar’ : vertical bar plot
- ‘barh’ : horizontal bar plot
- ‘hist’ : histogram
- ‘box’ : boxplot
- ‘kde’ : Kernel Density Estimation plot
- ‘density’ : same as ‘kde’
- ‘area’ : area plot
- ‘pie’ : pie plot
- ‘scatter’ : scatter plot
- ‘hexbin’ : hexbin plot
The plotting power of Pandas is limited compared to other Python visualization packages, e.g., Matplotlib, seaborn. Oftentimes, we only use pandas.plot function to explore data.
further reading: Overview of Python Visualization Tools
data = pd.DataFrame({'count':np.random.randint(0,1000,500)})
data.dtypes
data.plot(y='count', kind='hist')

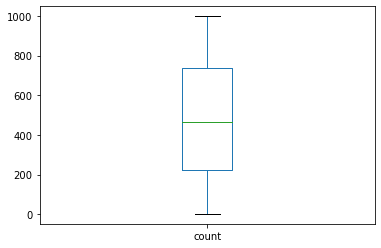
data.plot(y='count',kind='box')
Gotchas¶
Always uses loc() and iloc() to do indexing/slicing to avoid confusion¶
Situation 1: integers as row labels¶
#example 1: A Series with integers as index labels.
data = pd.Series(np.random.random(5),index=[2,3,4,8,6])
data
#What will happen? we are selecting the first item or the item with a label=0?
data[0]
data.loc[2]
data.iloc[0]
Situation 2: Dataframe¶
#example 2: dataframe
data = pd.DataFrame(np.random.random((3,4)),columns=['a','b','c','d'], index=['a','b','c'])
data
data['a'] #returns a column
data[0]# returns what?? the first column or the first row?
data.iloc[0]
Label-based slicing is inclusive in Pandas¶
The end bound of the slice in .loc() is included, which is different from the default slicing behavior of Python.
data = pd.Series(np.random.randint(0,100,10),index=range(0,10))
data
#use iloc
data.iloc[0:2] # select the first two rows
data.loc[0:2] # the end point of this slice is included.
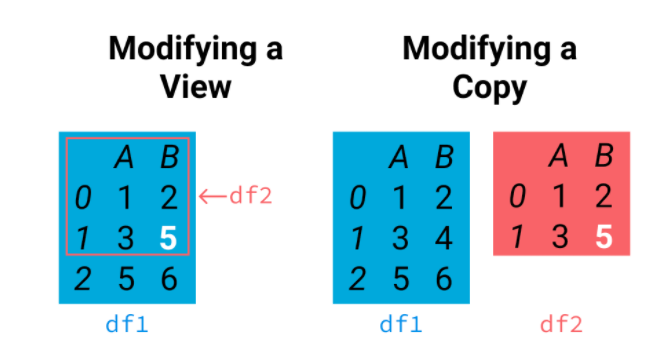
Copy Vs. View: Chained indexing¶
df = pd.read_csv("https://raw.githubusercontent.com/s4-web/pythontraining/main/data.csv")
df
Task: Change Kevin's Score to 100
#Solution1: Find the row which belongs to Kevin and then update its score
df2 = df.copy() # this creates a coopy of df
x = df2[df2.Name == "Kevin"] #Problem happens to this line. This leads to a copy, rather than a view to its orignial df2
x['Score'] = 100
df2
Where is the problem? Okay, the problem happens to the statement x = df2[df2.Name == "Kevin"]. This line returns a new copy of the selected rows. When you move to the next line where you want to update the score, it turns out you are manipulating the value of a new variable rather than the original data.
df2[df2.Name=='Kevin']['Score'] == 10 is functionally the same as the aforementioned example.
##Solution 2: squeeze all the conditions in a single loc call
df1 = df.copy()
df1.loc[df1.Name == 'Kevin', "Score"] = 100
df1
Rules to follow: Copy Vs. View (Source: Stackflow)